Twisted服务器开发技巧
Twisted是一个非常具有想像力的框架。我已经被它的代码所折服,我想在我下面再使用python开发网络应用时,可能只会选用Twisted了。但是,一个真正达到性能优化服务器,还是需要我们在程序中真正良好的去应用Twisted的各种工具的。 最常见的情况就是我们将一个非阻塞的应用中,加入了长时间的处理过程,从而达到了阻塞的效果,从而让大家都因为一位同志的长时工作而等待。
先来看看下面的这段代码:
1 from twisted.internet import protocol, reactor
2 from twisted.protocols import basic
3 class FingerProtocol(basic.LineReceiver):
4 def lineReceived(self, user):
5 self.transport.write(self.factory.getUser(user)+"\r\n")
6 self.transport.loseConnection()
7 class FingerFactory(protocol.ServerFactory):
8 protocol = FingerProtocol
9 def __init__(self, **kwargs): self.users = kwargs
10 def getUser(self, user):
11 return self.users.get(user, "No such user")
12 reactor.listenTCP(1079, FingerFactory(hd='Hello my python world'))
13 reactor.run()
它可能是我们所写的第一个Twisted服务器。可能所有人都会认为这样的操作已经不会有什么问题了。但是显然,在这里我们的getUser更多的情况下可能会是从数据库中或是LDAP服务器上获取相关的信息。哪么最好的处理就是将get操作以非即时方式返回,以避免发生处理的阻塞。哪么就需要使用Deferreds了:
1 from twisted.internet import protocol, reactor, defer
2 from twisted.protocols import basic
3 class FingerProtocol(basic.LineReceiver):
4 def lineReceived(self, user):
5 self.factory.getUser(user
6 ).addErrback(lambda _: "Internal error in server"
7 ).addCallback(lambda m:
8 (self.transport.write(m+"\r\n"),
9 self.transport.loseConnection()))
10 class FingerFactory(protocol.ServerFactory):
11 protocol = FingerProtocol
12 def __init__(self, **kwargs): self.users = kwargs
13 def getUser(self, user):
14 return defer.succeed(self.users.get(user, "No such user"))
15 reactor.listenTCP(1079, FingerFactory(hd='Hello my python world'))
16 reactor.run()
这里getUser返回的是defer处理过的一个事务,而addCallback方法注册了defer中处理完成后的返回事件。这样,事务的处理就可以在另一个事件可调度的情况下进行了。从而避免了因一个用户的处理阻塞的情况下,让所有的用户都停止了响应。
第二种优化的方法,可以只用下图来解释。即,使用轻量级的线程池(PreProcess)对所有请求进行预处理,所有不需要I/O执行时间很短的请求直接执行,如果是需要磁盘I/O的则放入下一级阻塞队列,有单独的线程池来处理这些请求。详见下图:
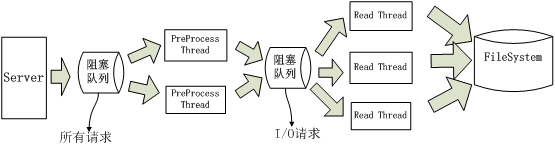
第一级请求使用自己已有的线程池,不再多说。I/O请求+二级线程池可以使用twisted提供的ThreadPool机制来实现。而我所说的优化正是使用此方法,代码很简单,如下:
deferred = threads.deferToThread(data_loader.get, sn)
deferred.addCallback(self.loader_callback, (req, other_data))
解释一下:
threads.deferToThread将会将data_loader.get放入reactor线程池的队列,并返回一个defer对象。data_loader.get由reactor的线程池进行执行,执行完成后放入reactor的队列,然后由reactor主线程来调用deferred.addCallback中注册的回调函数。所以回调函数是不会跨线程调用的,如果在回调函数中调用一些不可跨线程的应用(如,memcached客户端)也可放心使用,这也正是选择reactor的线程池作为二级线程池的原因之一。
选择reactor的线程池作为二级线程池的原因二:回调函数。因为Read Thread将自己负责恢复请求,所以回调函数必不可少。
接下来深入twisted源码探究此方法的原理,以下代码均是节选自twisted2.0.0源码,其他版本大致相同:
[python]
def deferToThread(f, *args, **kwargs):
d = defer.Deferred()
from twisted.internet import reactor
reactor.callInThread(_putResultInDeferred, d, f, args, kwargs)
return d
def _putResultInDeferred(deferred, f, args, kwargs):
from twisted.internet import reactor
try:
result = f(*args, **kwargs)
except:
f = failure.Failure()
reactor.callFromThread(deferred.errback, f)
else:
reactor.callFromThread(deferred.callback, result)
-----摘自threads.py
[python] view plaincopy
def callInThread(self, _callable, *args, **kwargs):
if not self.threadpool:
self._initThreadPool()
self.threadpool.callInThread(_callable, *args, **kwargs) //由线程池执行具体的读取操作
def callFromThread(self, f, *args, **kw):
...
self.threadCallQueue.append((f, args, kw)) //放入主线程队列,由主线程执行回调函数
self.wakeUp()
...
-----摘自base.py
注:callInThread/allFromThread,前者是放入线程池执行,后者是reactor的队列里,由reactor的主线程来执行。
至于threadpool的代码在twisted/python/threadpool是一个线程池
第三种方法是使用经典的服务器模型的select(epoll)异步I/O。使用twisted框架中的reactor(epoll/select)+reader,将磁盘I/O封装为reader,交给reactor来管理,磁盘I/O完成后调用回调函数将数据返回发送改请求的客户端。这样既不会因为I/O阻塞请求处理线程也不会如方法二一样因为I/O阻塞读取线程,详见下图:
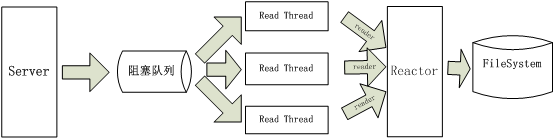
reactor(epoll/select)+ reader的方法需要继承abstract.FileDescriptor并且实现其几个方法,而twisted框架中的网络(TCP/UDP)、标准I/O、进程都有类似的实现。使用时传入文件描述符,如下:
[python]
fileReader = FileReader(fd, loader_callback, other_data)
reactor.addReader(fileReader)
FileReader类的实现如下:
[python]
class FileReader(abstract.FileDescriptor):
def __init__(self, fd, result_callback, args):
...
self.fd = fd
self.setNonBlocking(self.fd)
self.dataRecieved=result_callback
self.args=args
self.all_data=""
def setNonBlocking(self, fd):
...
def fileno(self):
return self.fd
def connectionLost(self, reason):
sys.close(self.fd)
def doRead(self)://fdesc.readFromFD(self.fd, self.dataReceived)
data = os.read(self.fd, 10240) //每次读取1M
self.all_data += data
if not data:
self.dataRecieved(self.all_data , self.args)
return CONNECTION_LOST
自己实现的reader并没有使用类似其他标准实现中的fdesc.readFromFD(self.fd, self.dataReceived)来读取数据,因为该函数中提供的回调函数不允许传参,所以自己将fdesc实现在了FileReader内。
下面是此方法的理论依据:
[python]
def addReader(self, reader):
fd = reader.fileno()
if not reads.has_key(fd):
selectables[fd] = reader
reads[fd] = 1
self._updateRegistration(fd)
def _updateRegistration(self, fd):
...
mask = 0
if reads.has_key(fd): mask = mask | select.POLLIN
poller.register(fd, mask)
def _doReadOrWrite(self, selectable, fd, event, POLLIN, POLLOUT, log,
faildict={
error.ConnectionDone: failure.Failure(error.ConnectionDone()),
error.ConnectionLost: failure.Failure(error.ConnectionLost())
}):
...
if event & POLLIN:
why = selectable.doRead()
inRead = True
...
if why:
self._disconnectSelectable(selectable, why, inRead)
-----摘自pollreactor.py
[python]
def _disconnectSelectable(self, selectable, why, isRead, faildict={
error.ConnectionDone: failure.Failure(error.ConnectionDone()),
error.ConnectionLost: failure.Failure(error.ConnectionLost())
}):
...
selectable.connectionLost(f)
[python]
def _disconnectSelectable(self, selectable, why, isRead, faildict={
error.ConnectionDone: failure.Failure(error.ConnectionDone()),
error.ConnectionLost: failure.Failure(error.ConnectionLost())
}):
...
selectable.connectionLost(f)
...